
Quality Assistance in Data Engineering: The Future of Scalable, Reliable Data Pipelines
The Quality Assistance model is transforming how modern data teams deliver reliable pipelines at scale. Instead of relying on a siloed QA function, quality becomes a shared responsibility embedded throughout the data lifecycle.

In modern oftware development, the Quality Assurance (QA) function is evolving. Traditional QA, where testing is owned by a separate team, is no longer scalable, especially in fast-moving, data-driven organizations.
Thus the Quality Assistance model: a forward-thinking approach that shifts quality ownership to the entire team, while enabling QA professionals to act as coaches, enablers, and strategists rather than testers.
This model has gained popularity in software engineering, but how does it translate to data engineering? For this, let’s understand first:
What is the Quality Assistance Model?
In a nutshell, Quality Assistance means everyone is responsible for quality.
Instead of a siloed QA team that tests everything after it's built, Quality Assistance emphasizes building quality from the start. QA specialists become advisors who help engineers, analysts, and data scientists adopt the tools, mindset, and practices needed to deliver high-quality data products.
Traditional QA vs Quality Assistance:
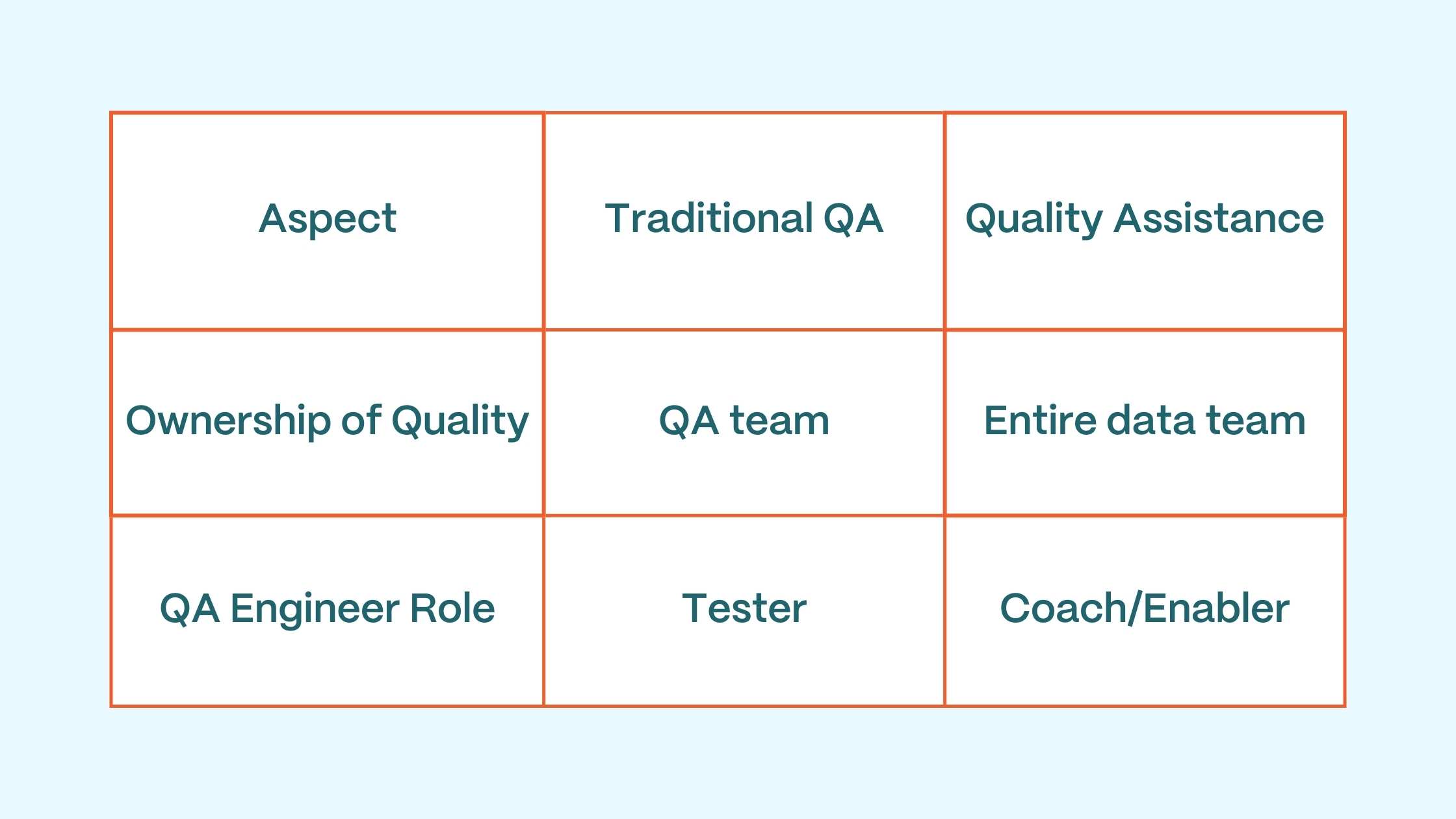
Why Traditional QA Fails in Data Engineering? Data engineering brings unique challenges:
- Complex pipelines with many moving parts (ETL/ELT, streaming, APIs)
- Dependencies on external data sources
- Schema drift and data inconsistency
- Late detection of issues (e.g., incorrect aggregates, missing values)
In traditional QA, these issues are often identified after the data is loaded into a warehouse, sometimes days or weeks too late, which is a significant problem.
Why Quality Assistance Works Better for Data Teams?
The Quality Assistance model addresses these pain points by:
- Empowering data engineers and analysts to test early and often
- Shifting from reactive testing to proactive design and validation
- Encouraging automation and tooling as a first-class citizen
- Promoting collaboration between QA, engineers, and business stakeholders
Implementing Quality Assurance in Data Engineering:
Here’s how we can embed the QA model into data engineering workflows.
1. Promote Testable Data Pipelines just like software code.
2. Shift Testing Left in the ETL Process, i.e. catch issues before they hit the data warehouse.
3. Coach, instead of owning, which means if you're a QA or data quality specialist:
- Don’t write every test yourself
- Teach engineers and analysts how to write meaningful data tests
Benefits of Quality Assistance in Data Engineering:
- Faster feedback loops
- Increased trust in data across the organization
- Shared responsibility implies more test coverage
- QA becomes a strategic partner, not a bottleneck
- Empowered engineers means happier teams
At last, we can say that the Quality Assistance model is a game-changer for data engineering teams. By enabling rather than owning quality, teams move faster, reduce errors, and ship more reliable data products.
As data pipelines grow in complexity, the only scalable path forward is to make quality everyone’s job with quality engineers leading the charge as coaches and catalysts.
Share
Related Blogs

AI systems are powerful but lack persistent memory, often “forgetting” context across sessions. This blog explores how Knowledge Graphs, Cognee, and Model Context Protocol (MCP) work together to solve AI amnesia, enabling structured memory, contextual reasoning, and seamless AI-to-data connectivity.
What started as a small limitation in a client Streamlit project turned into a widely used open-source Python library. This is a practical story about learning beyond comfort zones, building what doesn’t exist, and how real-world problems can create value far beyond a single project.
%20Choosing%20Between%20Apache%20Iceberg%20and%20Delta%20Lake.jpg)
As data lakes scale and power AI-driven analytics, schema evolution has become a critical engineering challenge. This blog explores how Apache Iceberg and Delta Lake enable teams to manage schema changes safely, without breaking pipelines, analytics, or trust in data.