
Schema Evolution in Modern Data Lakes (2026): Choosing Between Apache Iceberg and Delta Lake
As data lakes scale and power AI-driven analytics, schema evolution has become a critical engineering challenge. This blog explores how Apache Iceberg and Delta Lake enable teams to manage schema changes safely, without breaking pipelines, analytics, or trust in data.
%20Choosing%20Between%20Apache%20Iceberg%20and%20Delta%20Lake.jpg)
In the modern data landscape, data lakes have become essential for storing massive volumes of unstructured and semi-structured data. However, as organizations grow and data requirements shift, the structure or scheme of that data also changes. This evolution poses challenges in maintaining consistency and data quality across the data lake.
To address this, tools like Apache Iceberg and Delta Lake offer reliable solutions for managing schema evolution effectively. These open-source technologies help ensure that your data lake remains scalable, consistent, and easy to query even as data structures change over time.
Why Schema Evolution Matters
Data lakes often aggregate data from various systems, each with its own schema. Over time, as new fields are added or existing ones are modified or removed, it becomes critical to manage schema changes without breaking data pipelines.
Failing to manage schema evolution properly can lead to:
- Data inconsistencies: Causing errors in queries or misleading results.
- Operational complexity: Making it harder to integrate and process data across tools.
- Performance bottlenecks: As poorly structured data slows down analytics.
Schema evolution is not just about accommodating change, it’s about maintaining trust and reliability in your data ecosystem.
Apache Iceberg and Schema Evolution
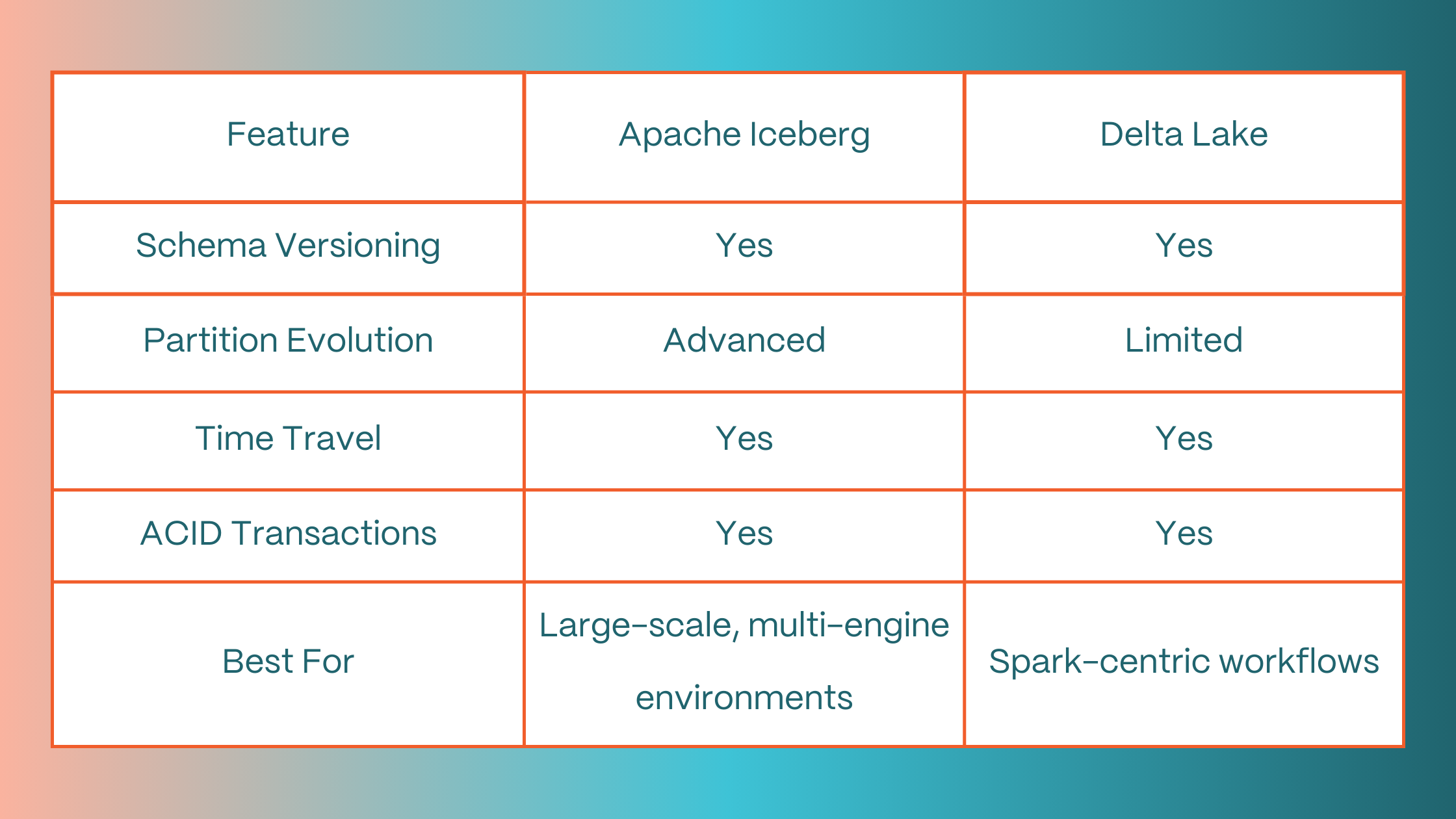
Apache Iceberg is an open-source table format optimized for large-scale analytics on data lakes. Designed with schema evolution in mind, Iceberg enables developers to manage table changes efficiently without rewriting large datasets.
Key capabilities:
- Column Additions & Deletions: Modify the schema without impacting existing data.
- Schema Versioning: Track and query past schema states for audits or troubleshooting.
- Partition Evolution: Update partition strategies over time without recreating tables.
Iceberg ensures that schema changes are backward-compatible, preserving data accessibility and analytics workflows even as the structure evolves.
Delta Lake and Schema Evolution
Delta Lake, built on top of Apache Spark, offers another powerful option for managing schema changes in a data lake environment. It combines ACID transactions with schema management, making it ideal for both batch and streaming workloads.
Key features include:
- Schema Enforcement: Validates incoming data against the existing schema.
- Automatic Schema Updates: Optionally updates the schema when new data is ingested.
- Time Travel: Query previous versions of data and schema using timestamps.
- Transactional Integrity: Uses ACID principles to ensure safe schema modifications.
- Support for Upserts: Handles slowly changing dimensions through merge operations.
Delta Lake is especially useful when your pipeline relies heavily on Spark and demands strict schema governance.
Choose Iceberg if you're dealing with huge datasets or need multi-engine support. Opt for Delta Lake if you're already using Spark and want native schema enforcement.
Conclusion
Managing schema evolution is essential for maintaining data integrity, especially as organizations scale and diversify their data sources. Tools like Apache Iceberg and Delta Lake simplify this process, enabling robust data governance and flexible data architectures.
By choosing the right framework:
- You reduce the risk of data inconsistencies.
- You streamline analytics and data processing.
- You prepare your data infrastructure for long-term growth and change.
Whether you choose Iceberg or Delta Lake, both provide the foundation needed to build scalable, future-ready data lakes.
Tip:
- If you’re operating across cloud providers or require deep schema versioning and partition evolution, Iceberg is ideal.
- If you’re running Spark pipelines and need real-time schema enforcement, Delta Lake is your best bet.
Share
Related Blogs

AI systems are powerful but lack persistent memory, often “forgetting” context across sessions. This blog explores how Knowledge Graphs, Cognee, and Model Context Protocol (MCP) work together to solve AI amnesia, enabling structured memory, contextual reasoning, and seamless AI-to-data connectivity.
What started as a small limitation in a client Streamlit project turned into a widely used open-source Python library. This is a practical story about learning beyond comfort zones, building what doesn’t exist, and how real-world problems can create value far beyond a single project.
Data modeling isn’t about diagrams, it’s about building shared understanding that survives business change. This blog breaks down practical, real-world data modeling principles every corporate engineer should master to build reliable, scalable, and trusted data systems. No theory. Just judgement earned through experience.